
[첨단 헬로티]
머신비전산업에서 인공지능 기술(머신러닝, 딥러닝)이 빠르게 확산되고 있다. 인공지능 기술을 통해 기존의 컴퓨터비전 기술로는 어려웠던 검사가 가능해질 뿐만 아니라 ‘데이터의 자기 학습’으로 보다 빠르고 쉬우며 신뢰성과 유연성을 갖춘 머신비전 검사가 가능해졌다. 이에따라 자연스럽게 인공지능 기술에 대한 관심이 높아지고 있다. 국내 대표적인 머신비전 전문업체인 라온피플은 ‘LAON PEOPLE’s 머신러닝 아카데미’를 통해 인공지능의 대표적인 기술인 머신러닝 기술에 대해 연재한다.
1. Overview (머신러닝의 정의와 분류)

Machine Learning의 정의
1959년 Arthur Samuel은 기계학습에 대해서 다음과 같이 정의를 했다.
“Field of study that gives computers the ability to learn without being explicitly programmed”
즉, 이런 경우에는 이렇게 동작하고, 저런 경우에는 저렇게 동작하라는 등 가능한 모든 경우의 수를 프로그래머가 정의해주지 않더라도, 데이터를 통한 학습을 하여 최적의 판단이나 예측을 가능하게 해주는 것을 말한다.
가령 필기체를 인식하는 프로그램을 개발한다고 가정을 해보자. 사람들이 매우 다양한 방법으로 손글씨를 쓰기 때문에, 손글씨 영상에 대해 평균화 작업 및 기타 전처리 작업을 하더라도, 프로그래머가 사전에 모든 경우의 수를 프로그램 해준다는 것은 사실상 불가능하다.
이런 경우에 기계 학습이 개념이 필요해진다. 마치 사람들이 의식적인 혹은 무의식적인 학습을 통해 판단/구별/인지하는 것을 배우듯이, 적절한 기계 학습법을 통해 사람의 직접적인 개입없이 글자를 인식하거나, 음성을 인식하는 것들이 가능해진다.
Machine Learning의 분류
이런 기계학습은 data mining 또는 패턴 인식이라고도 불린다. 기계학습은 크게 지도학습 (supervised learning)과 비지도학습(unsupervised learning)으로 분류를 하고 있다. 하지만 경우에 따라 강화학습(reinforcement learning)을 추가하여 3가지로 분류를 하는 사람들도 있다.
지도학습(supervised learning)이란 어떤 입력에 대해서 어떤 결과가 나와야 하는지 사전 지식을 갖고 있는 경우에 해당 입력에 대해 특정 출력(label)이 나오도록 하는 규칙을 찾아낸다. 보통은 입력과 출력 쌍으로 구성되는 학습 데이터(training data)에 의해 입력으로부터 출력을 끌어내는 규칙(rule)을 발견하는 것을 학습의 목표로 하며, 흔히 말하는 회귀(regression) 방법이 여기에 해당한다. 현재까지 가장 많이, 그리고 활발하게 연구가 진행된 분야로 우리가 알고 있는 많은 학습 방법이 여기에 해당된다.
비지도학습(unsupervised learning)이란 입력은 있지만 정해진 출력이 없는 경우를 말하며, 순수하게 데이터들이 갖고 있는 속성들을 이용해 그룹으로 나누는 경우를 말하며, 지도학습이 회귀 방법을 사용하는 것과 달리, 분류(clustering)에 해당이 된다. 가령 사람들이 나이, 학력, 성별, 출생 지역 등의 조합에 따라 어떤 정당을 지지하는지 살펴보는 것도 자율 학습에 속한다. 일반적으로는 시장 조사, 컴퓨터 클러스터링, 그림이나 동영상에 대한 auto-tagging 등에 사용이 된다.
강화학습(reinforcement learning)은 로봇의 학습 등에 사용할 수 있으며, 자신과 환경과의 상호 관계에 따라 자신의 행동을 개선해 나가는 학습법을 말한다. 가령 칭찬을 받은 행위는 더욱 많이 하고, 벌을 받을만한 행위는 줄이는 것과 마찬가지로 적응성을 통해 학습을 강화해가는 것을 말한다. 물론 학습의 결과가 즉각적으로 나타나는 경우에 효과적이라고 할 수 있다.
2. Supervised Learning
지도학습(Supervised Learning) 개요
Supervisor를 사전에서 찾아보면 작업 현장을 지휘 통제하는 ‘감독관’, 학생을 가르치고 인도하는 ‘지도교수’ 등의 의미를 갖고 있다. 그러므로 지도학습이란 이미 주어진 입력에 대해 어떤 결과가 나올지 알고 있는, 전문 용어로는 labeling이 된, 출력과의 관계를 이용해서 데이터들을 해석할 수 있는 모델을 만들고, 그것을 바탕으로 새로운 데이터를 추정(predict)하는 것을 말한다.
즉, 과거의 지식을 이용해 미래를 예측하는 것과 마찬가지이다. (그림 1참조)
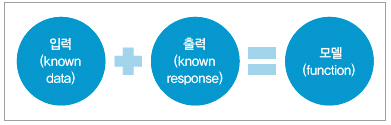
▲ 그림 1
좋은 학습 결과를 얻으려면, 일반적으로 훈련 데이터(training data)의 양이 많아야 하며, 훈련 데이터가 범용성을(generalization) 갖고 있어야 한다.
지도학습(Supervised Learning) 단계
지도학습은 다음 단계를 거친다
1. 학습에 사용할 훈련 데이터를 정한다.
ㆍ훈련 데이터는 모델의 성패 여부를 결정하기 때문에 잘 선정을 해야 한다.
2. 훈련 데이터를 모은다.
3. 입력의 특징(feature)을 어떻게 표현할 것인지 결정한다.
ㆍ일반적으로는 벡터 형태로 표현을 한다. 차원의 저주(curse of dimensionality)에 빠지지 않도록 특징의 수를 너무 크게 해서는 안된다.
4. 학습 알고리즘을 결정한다.
ㆍ지도학습 방법을 사용할 알고리즘이 매우 많고 그 특성도 다양하기 때문에 적용할 분야에 맞춰 적절한 알고리즘을선택해야 한다.
5. 훈련 데이터를 이용해 학습 알고리즘을 실행한다.
6. 만들어진 모델의 정확도를 평가한다.
ㆍ보통은 훈련 데이터와 다른 테스트 데이터를 이용해 이 과정을 수행한다.
지도학습(Supervised Learning) 알고리즘
대표적인 지도학습 알고리즘의 종류는 다음과 같다.
. Artificial neural network
. Boosting
. Bayesian statistics
. Decision tree
. Gaussian process regression
. Nearest neighbor algorithm
. Support vector machine
. Random forests
. Symbolic machine learning
. Ensembles of classifiers
3. Unsupervised Learning (자율학습, 비지도학습)
Supervised Learning(지도학습)과 Unsupervised Learning(비지도학습)
기계학습을 연구하는 사람들의 꿈은 데이터만 넣어주면 모든 것을 알아서 척척 처리해주는 시스템일 것이다. 하지만, 앞서 살펴본 것처럼 지도 학습을 통해 특정 입력을 가했을 때 어떤 출력을 내줘야 한다는 것은 이미 알고 있는 시스템에서도 요원한 일이다.
이것은 학교에서 선생님이 친절하게 가르쳐주더라도 시험에서 모든 사람이 만점을 받을 확률이 거의 없는 것과 마찬가지이다.
자율학습이란 그런 선생님의 지도 없이도 만점을 받기를 기대하는 것과 같기 때문에, 훨씬 더 어렵다고 볼 수 있다. 지도학습의 경우는 훈련(training)을 통해 error function 혹은 loss function을 구할 수 있으며, 이 값을 피드백(훈련 결과의 양호함을 판단)으로 활용하여 모델을 개선시킬 수 있으나, 자율학습의 경우는 이렇게 이용할 수 있는 수단이 없다는 점에서 다르다.
어찌 보면, 통계에서 밀도를 추정하는 것과 비슷하다.
기계학습의 종류 중 하나인 ‘강화학습(reinforcement learning)’의 경우는 지도학습의 경우처럼, 사전에 기대하는 결과가 있는 것은 아니지만, 동작하는 환경과의 상호 작용을 통해, 그 결과로서 보상(reward) 혹은 벌(punishment)을 받기 때문에 어떤 의미에서 보면 자율학습에 비해 쉽다고(?) 할 수도 있다.
Unsupervised Learning (비지도학습) 개요
기대할 수 있는 올바른 답도 없고, 결과로서의 보상 또는 벌도 없다면, 도대체 어떻게 학습을 수행할 수 있을까? 하지만, 결론부터 말하면 학습이 가능하다.
기계학습의 목표가 입력들이 주어졌을 경우 그 입력에 대한 결정을 하고(decision making) 새로운 입력이 들어올 경우 결과를 예측하는(predicting future input) 모델(representation)을 만드는 것이기 때문에, 이것을 가능하게 하는 프레임워크를 만들 수 있다.
자율학습의 대표적인 2가지 예는 분류(clustering)과 차원 축소(dimensionality reduction)이다. 차원 축소의 기술로는 PCA(Principle Component Analysis), ICA(Independent Component Analysis), Non-negative matrix factorization 및 SVD(Singlular Value Decomposition) 기술 등이 있다.
이것들 각각에 대한 자세한 내용은 추후에 다룰 예정이다.
초기 신경망 회로(neural network)는 지도학습을 이용해, 인쇄된 문자 인식, 필기체 인식 및 음성 인식에서 탁월한 효과를 보였다. 최근은 SOM(Self-Organizing Map)과 ART(Adaptive Resonance Theory)와 같은 자율학습(Unsupervised learning)을 이용한 응용 연구가 활발히 진행이 되고 있다.
4. Reinforcement Learning (강화학습)
Reinforcement Learning(강화학습) 개요

▲ 그림 2
Reinforcement를 사전에서 찾아보면, 군대나 경찰 등의 ‘증원 요원’ 또는 감정이나 생각 등의 ‘강화’라는 뜻으로 사용됨을 알 수 있다. 기계학습(machine learning)의 방법 중 하나로 reinforcement learning이라는 개념이 사용될 때, 우리말로는 대부분 ‘강화학습’이라는 말로 번역이 된다.
왜 학습에 ‘강화’라는 말이 붙게 되었을까?
이것을 설명하기 전에 개를 훈련시키는 것을 상상해보면 이해가 쉽다. 그림 2와 같이 보통 개를 훈련시키는 경우 개가 훈련을 잘 따르면 ‘상(reward)’을 주고, 잘 따르지 못하면 ‘벌(punishment)’을 준다. 개는 상과 벌을 통해 훈련자가 원하는 방향으로 학습을 하게 된다.
여기서 훈련에 잘 따른다는 것은 지도학습(supervised learning)의 경우처럼, 명확한 관계 (즉, 오직 한가지 결과)만 기대할 수 있는 것이 아니라, ‘잘 했다’라는 것은 여러 가지 상황이 있다는 점에 주목해야 한다.
Reinforcement Learnin(강화학습)의 적용
강화라는 말을 사용한 이유는 상과 벌이라는 보상을 통해 ‘현재의 행위의 그 방향’으로 혹은 ‘반대방향’으로 그 행위를 강화하는 학습 방법으로, 상을 최대한 많이 받을 수 있는 방향으로 학습하는 방법이며, 로봇이나 인공지능 분야에서 많이 사용된다.
지도학습의 경우처럼, 입력과 출력이 명확한 관계를 갖고 있는 상황이 아니라, 환경과의 상호 작용의 결과로서 학습을 하거나, 훈련 모델을 사전에 명확하게 기술하기 어려운 경우에 적용할 수 있는 학습 방법이다.
강화학습은 보상을 최대화시키기 위해 무엇을 할 것인가를 배우는 것이다. 학습자는 지도학습의 경우처럼 사전에 어떤 행위를 하지 할 것인지 듣고 하는 것이 아니라, 시행착오를 거치면서 보상을 최대화시키는 것을 배우는 것이다.
흥미로운 사실은, 어떤 행위에 대한 보상 뿐만 아니라, 다음 상황 및 그것의 결과로서의 보상에 영향을 받게 된다는 점이다. ‘시행착오를 통한 탐색 혹은 결정(decision making through trial-and-error)’ 및 ‘지연 보상(delayed reward)’은 강화학습을 다른 학습과 구별하게 만드는 두 가지 특징이다.
강화학습(줄여서, RL이라는 말을 많이 사용함)의 표준 프레임워크에서는 학습자(가령, 동물이나 로봇)는 반복적으로 환경의 상태를 주시하면서, 어떤 행위를 할 것인지를 선택한다.
학습자는 상(reward)을 최대화 시키기 위해, 결과를 수치적으로 파악할 수 있어야 하며, 장시간 동안의 합을 최대화시키는 방향 혹은 미래에 받을 상의 평균을 최대화시키는 방향으로 학습을 배우게 된다.
강화학습은 game theory, control theory, simulation-based optimization, multi-agent systems, genetic algorithms, 및 operation research 등 다양한 분야에서 활발하게 연구가 되고 있다.
다음호에서는 Part II. Neural Networks에 대해 알아본다.
(주)라온피플












































